By Lauren Snyder (TIB)
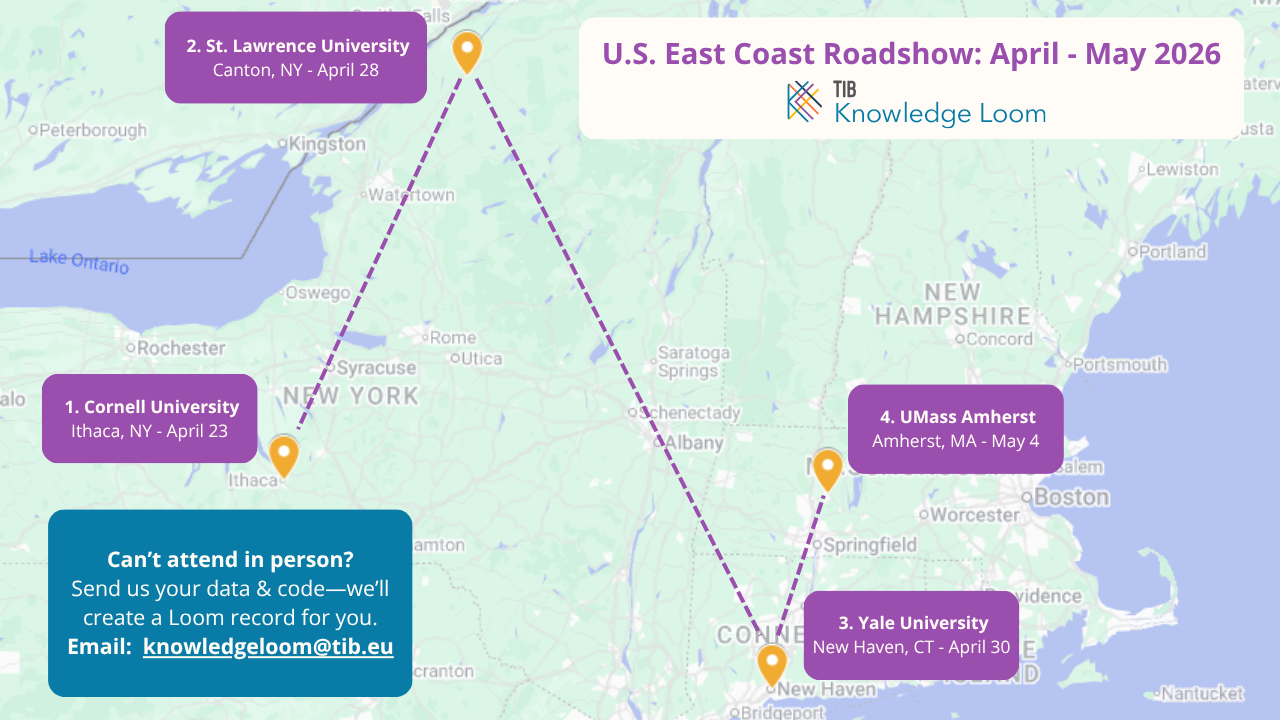
Shortly after presenting the TIB Knowledge Loom at the FAIR2Adapt General Assembly in March, I set off to the U.S. East Coast for a four-stop roadshow to present and demo the emerging Open Science digital library. The tour kicked off at Cornell University on April 23, followed by stops at St. Lawrence University, Yale University, and UMass Amherst. The goal was to meet with researchers, data stewards, and librarians to introduce the Loom and collect feedback to guide future development.

It was an adventure in every sense of the word, from resolving last-minute flight cancellations and accommodation changes to navigating winding Adirondack mountain roads and reconnecting with friends and colleagues.
What we learned
Across all four stops, a few themes consistently emerged. Faculty immediately saw the educational potential of the TIB Knowledge Loom, which presents scientific findings alongside the data, code, and analyses used to produce them. The Loom is a valuable resource for instructors who want to create activities that challenge students to reproduce an author’s final results using the raw data. And while the Loom’s Insights page is still in development, it demonstrates the value of being able to see how authors implemented specific R and Python packages in their research.
Researchers and data managers were also struck by the ability to assign a DataCite DOI to individual Loom statements, making it possible to cite not just an article but a specific result and the exact analysis that produced it.
That said, researchers were clear that time is their most precious resource. For the Loom to be widely adopted, it needs to integrate naturally into workflows researchers already use, making reproducibility and reusability a seamless step rather than an additional task. This is something we have already been learning through our work with FAIR2Adapt, where the goal is to make FAIR tools as easy as possible for researchers to use.
A strategic direction
Conversations at Yale gave us some exciting ideas in this direction. Data repositories are infrastructures that researchers already know and trust. They play an essential role in the long-term storage of research assets, such as data and code, that researchers are increasingly required to publish. One idea is to integrate the Loom with existing data repositories by positioning it as a scientific knowledge layer that sits atop these infrastructures, providing an independent, third-party reproducibility check. This would allow us to tap into workflows researchers already use rather than asking them to adopt a new one.
What’s next

Feedback from the roadshow will directly shape how the Loom develops in the months ahead. At UMass Amherst, researchers suggested that a dedicated form to capture the information needed to create a Loom record could streamline the submission process, and we are actively working on this. At Cornell, data stewards and statisticians were excited about the potential of Loom records to strengthen the peer review process. We are moving in this direction by developing user accounts that will allow researchers to submit embargoed Loom records during peer review, making the content accessible only to reviewers.
Whether you have a peer-reviewed article with associated data and code to contribute, or are interested in exploring a collaboration, we would love to hear from you: knowledgeloom@tib.eu. The roadshow may be over, but the conversations it sparked are just beginning.